
NVIDIA Nemotron 3는 1M 컨텍스트와 하이브리드 MoE로 Qwen3 30B 대비 최대 3.3배 처리량을 제공합니다. 오픈 가중치·상업적 활용이 가능한 오픈 모델 패밀리입니다. AI 팩토리 레퍼런스 아키텍처와 결합하면 온프렘·코로케이션 기반 엔터프라이즈 AI 공장을 빠르게 구축할 수 있습니다.
2025년 12월, NVIDIA가 NVIDIA Nemotron 3 오픈 모델 패밀리와 HPE AI 팩토리 레퍼런스를 동시에 내놓았습니다. 1M 컨텍스트와 하이브리드 Mamba Transformer MoE, 오픈 가중치 조합은 단순 LLM 출시를 넘어 기업용 AI 인프라 전략을 다시 짜야 할 만한 변화입니다.
2024년까지는 클라우드 전용 LLM API가 기본 옵션이었다면, 2025년부터는 온프렘·코로케이션·하이브리드에서 자가 AI 공장을 짓는 선택지가 현실화되고 있습니다. Nemotron 3는 NVIDIA 풀스택(GPU·네트워크·소프트웨어)을 전제로 이 전환의 중심에 놓인 모델 패밀리입니다.
아래에서 Nemotron 3 패밀리 구조와 하이브리드 Mamba Transformer MoE 아키텍처, 라이선스와 엔터프라이즈 도입 관점, AI 팩토리 레퍼런스 아키텍처 활용 포인트를 순서대로 정리합니다. 끝에서는 Llama·Mistral·DeepSeek과 비교해 어떤 조직이 Nemotron 3를 선택하면 좋은지 다섯 가지 의사결정 기준을 제시합니다.
NVIDIA Nemotron 3 패밀리 구조: Nano·Super·Ultra 3단계 라인업
Nemotron 3 Nano·Super·Ultra 스펙과 타깃 워크로드 한 번에 보기
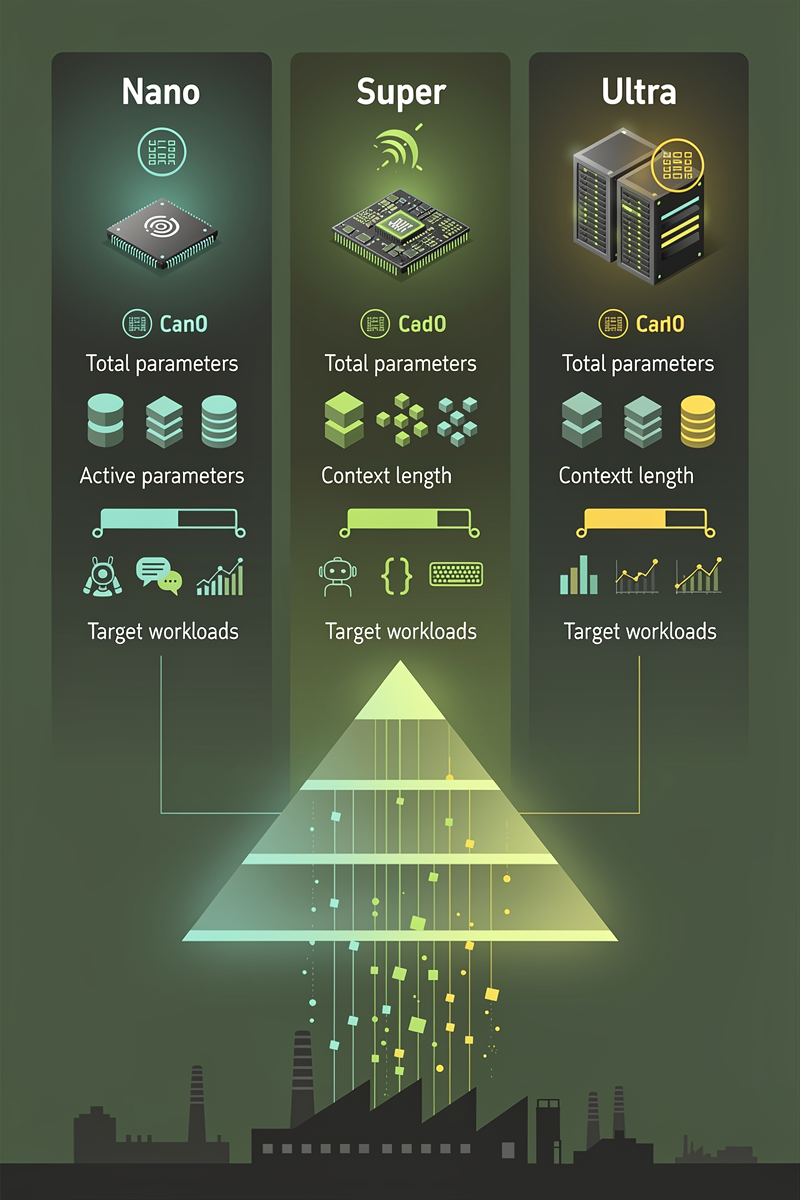
- Nemotron 3 Nano 30B 모델: 약 31.6B total / 3.2~3.6B active 파라미터, 1M 컨텍스트 지원, 단일 H200 기준 Qwen3 30B-A3B 대비 최대 3.3배 처리량. 에이전트·코딩·RAG용 범용 베이스로 설계됐습니다.
- Nemotron 3 Super: 약 100B total / 최대 10B active 파라미터, 1M 컨텍스트 지원. 멀티 에이전트 오케스트레이션과 고난도 reasoning 중심 상위 라인업으로, 2026년 상반기 공개 예정입니다.
- Nemotron 3 Ultra: 약 500B total / 최대 50B active 파라미터 플래그십, 1M 컨텍스트 기반. 대규모 에이전트 스웜과 고부하 엔터프라이즈 분석을 겨냥한 모델로, Blackwell 세대 GPU를 전제로 한 하이엔드 옵션입니다.
- 공통 특징: 하이브리드 Mamba Transformer MoE 구조와 NVFP4·A3B 같은 저정밀 포맷을 활용해, dense 모델 대비 고효율 추론과 높은 처리량을 확보한 오픈소스 LLM 패밀리입니다.
하이브리드 Mamba Transformer MoE 아키텍처로 처리량 3배 노리는 이유
하이브리드 Mamba Transformer MoE 아키텍처는 시퀀스 처리와 전역 주의(attention)를 분리해 효율과 품질을 동시에 노립니다. Mamba-2 계열 모듈이 긴 시퀀스를 선형에 가까운 복잡도로 처리하고, Transformer 블록이 전역 reasoning과 토큰 간 상호작용을 담당합니다.
MoE(Mixture-of-Experts)는 토큰마다 일부 전문가만 활성화해 연산량을 줄입니다. 동시에 코드·수학·자연어 등 특정 도메인에 특화된 서브모델을 활용합니다. Nemotron 3 Nano는 total 31.6B 중 약 3.6B만 active로 사용해 dense 30B보다 VRAM과 FLOPs를 크게 줄이는 구조를 채택합니다.
이 조합 덕분에 1M 토큰급 롱컨텍스트에서도 처리량이 유지되고, 코드·수학·에이전트 벤치마크에서 동급 dense 모델보다 고효율 추론 성능과 처리량 최적화 측면에서 우위를 보입니다.
1M 토큰 초장문 컨텍스트 지원이 여는 3가지 실전 워크플로
- 사내 지식베이스 통합 리서치: 수십 개 시스템 설계서와 정책 문서를 한 번에 넣고 질의하는 로컬 RAG 및 엔터프라이즈 검색 워크플로가 가능합니다. “어느 팀이 어떤 설계를 언제 바꿨는가” 같은 복합 질문도 한 세션에서 추적할 수 있습니다.
- 대규모 로그·트레이스 분석: APM·분산 트레이싱·보안 로그를 수십만 토큰 단위로 넣고 이상 징후와 근본 원인을 한 번에 분석합니다. 장애 타임라인과 구성 변경 내역을 한 세션 안에서 유지할 수 있습니다.
- 계약·규정 준수 검토: 장기 계약서와 규정집, 메일 스레드를 묶어 넣고 조항 충돌, 리스크, 변경 이력을 컨텍스트 손실 없이 검토할 수 있습니다. 법무·컴플라이언스 팀용 AI 에이전트에 특히 유용합니다.
Nemotron 3가 강한 3대 영역: 멀티 에이전트, 코딩, 로컬 RAG
멀티 에이전트 AI 시스템 구축에 Nemotron 3가 적합한 이유

에이전틱 AI는 여러 에이전트가 역할을 나눠 목표를 달성하도록 협력하는 구조입니다. 예를 들어 플래너·코더·실행기·평가자 에이전트가 티켓을 나눠 처리하는 패턴입니다.
NVIDIA Nemotron 3는 1M 토큰 컨텍스트와 하이브리드 MoE 구조로 에이전트 간 대화를 길게 유지하면서도 비용을 억제합니다. 코드·수학·툴 사용 벤치마크에서 강점을 보여 멀티 에이전트 AI 시스템 구축 시 플래너부터 액터까지 공통 패밀리로 쓰기 좋습니다.
또한 NVIDIA 풀스택(Blackwell GPU, TensorRT-LLM, SGLang, vLLM)과 결합하면 고동시성 에이전트 워크로드에서도 처리량을 안정적으로 확보할 수 있어, 엔터프라이즈 환경에서 멀티 에이전트 AI 시스템 구축에 적합합니다.
AI 코딩 어시스턴트: Nemotron 3 Nano 30B 모델로 할 수 있는 것들
- 코드 생성: LiveCodeBench 기준 상위권 코드 성능으로 서비스 스캐폴딩, 테스트 코드, 인프라 IaC 템플릿을 빠르게 생성합니다.
- 리팩토링: 레거시 모놀리식 코드베이스를 마이크로서비스나 서버리스 패턴에 맞춰 쪼개는 작업을 돕는 리팩토링 제안을 제공합니다.
- 코드 리뷰: 스타일·보안·성능 이슈를 한 번에 검토하고, 리뷰 코멘트와 패치 제안을 함께 내는 AI 코딩 어시스턴트 패턴을 구현할 수 있습니다.
- 성능·비용 관점: MoE 기반 구조 덕분에 동일 GPU에서 더 많은 개발자 세션을 동시에 처리해 GPU 자원 최적화 및 비용 절감을 기대할 수 있습니다.
로컬 RAG 및 엔터프라이즈 검색: 1M 컨텍스트의 현실적인 활용 패턴
대부분의 엔터프라이즈는 데이터 거버넌스와 규제로 핵심 문서를 클라우드 외부로 내보내기 어렵습니다. 이 환경에서 로컬 RAG 및 엔터프라이즈 검색은 온프렘 또는 코로케이션 환경의 LLM 서빙이 전제됩니다.
Nemotron 3는 1M 토큰 초장문 컨텍스트 지원 덕분에 인덱싱이 애매한 장문 PDF와 산재한 위키 페이지를 통째로 컨텍스트화하기에 유리합니다. 하이브리드 MoE 구조로 동일 하드웨어에서 더 많은 동시 쿼리를 처리해 검색·요약·질의응답 워크로드 비용을 낮출 수 있습니다.
GPU·네트워크·스토리지가 이미 NVIDIA 스택인 조직이라면 기존 쿠버네티스·서비스 메시 위에 Nemotron 3 기반 RAG 서비스를 비교적 간단히 올릴 수 있다는 점도 실무 장점입니다.
오픈 모델 Nemotron 3: 라이선스와 엔터프라이즈 도입 체크포인트
NVIDIA Open Model License 핵심: 무엇이 ‘오픈’이고 어디까지 쓸 수 있나
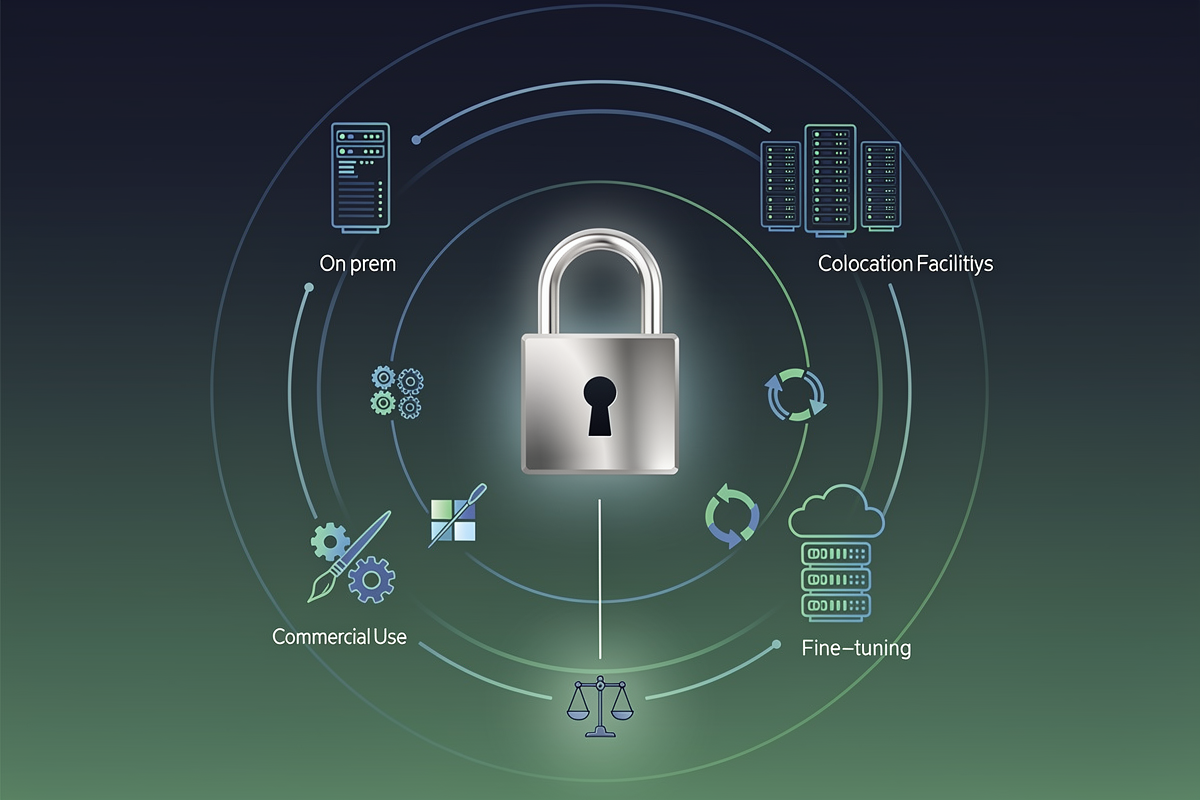
- 오픈 가중치: 모델과 파생 모델을 자유롭게 다운로드·사용·수정·파인튜닝할 수 있는 가중치 공개 구조입니다.
- 상업적 활용 허용: 제품·서비스에 모델을 포함해 판매할 수 있도록 상업적 사용이 명시적으로 허용됩니다.
- 온프렘·클라우드 제한 없음: 온프렘, 코로케이션, 퍼블릭 클라우드 등 배포 위치에 대한 별도 제한이 없는 오픈 모델 라이선스입니다.
- 재배포 조건: 원본 또는 파생 모델을 배포할 때 NVIDIA Open Model License 사본과 지정 문구를 포함해야 합니다.
- 책임·보증 부인: 모델은 “AS IS”로 제공되며, 출력물 책임과 규제 준수 의무는 전적으로 사용자에게 있다는 조항이 포함됩니다.
상업적 활용·온프렘 배포 전 기업이 반드시 확인해야 할 4가지
- 콘텐츠·규제 책임: 모델 출력에 대한 책임이 라이선시에게 있으므로, 개인정보·저작권·허위정보 필터링 체계를 별도로 구축해야 합니다.
- 재배포·서브라이선스 정책: 사내 플랫폼이나 고객 온프렘에 모델을 배포할 경우 라이선스 사본과 고지 문구 포함 여부를 점검해야 합니다.
- IP 소송 리스크 관리: NVIDIA 또는 제3자의 IP 침해를 주장하며 소송을 제기하면 라이선스가 종료될 수 있어, 특허 전략과 법무 검토가 필요합니다.
- 비용·효율성 검토: 자체 GPU 인프라 서빙 시 배치 전략과 양자화 수준을 설계해 GPU 자원 최적화 및 비용 절감을 달성해야 합니다.
오픈소스 LLM 패밀리 전략: Nemotron 3의 데이터·레시피 공개 의미
Nemotron 3는 모델 가중치뿐 아니라 데이터 구성, 평가 레시피, 추론 설정까지 폭넓게 공개하는 흐름을 보입니다. 이 수준의 공개는 단순 “무료 사용”을 넘어 재현 가능한 연구와 엔터프라이즈 검증을 가능하게 합니다.
조직은 사내 데이터로 파인튜닝한 결과를 공개된 평가 레시피에 그대로 태워 내부 품질을 외부 수치와 비교할 수 있습니다. 이는 벤더 종속을 줄이고, 여러 오픈소스 LLM 패밀리 간 공정한 비교와 장기적인 모델 포트폴리오 전략 수립의 기반이 됩니다.
AI 팩토리 레퍼런스 아키텍처: HPE·NVIDIA로 짓는 기업용 AI 공장
HPE AI 팩토리 레퍼런스 아키텍처 5계층 한 장으로 이해하기
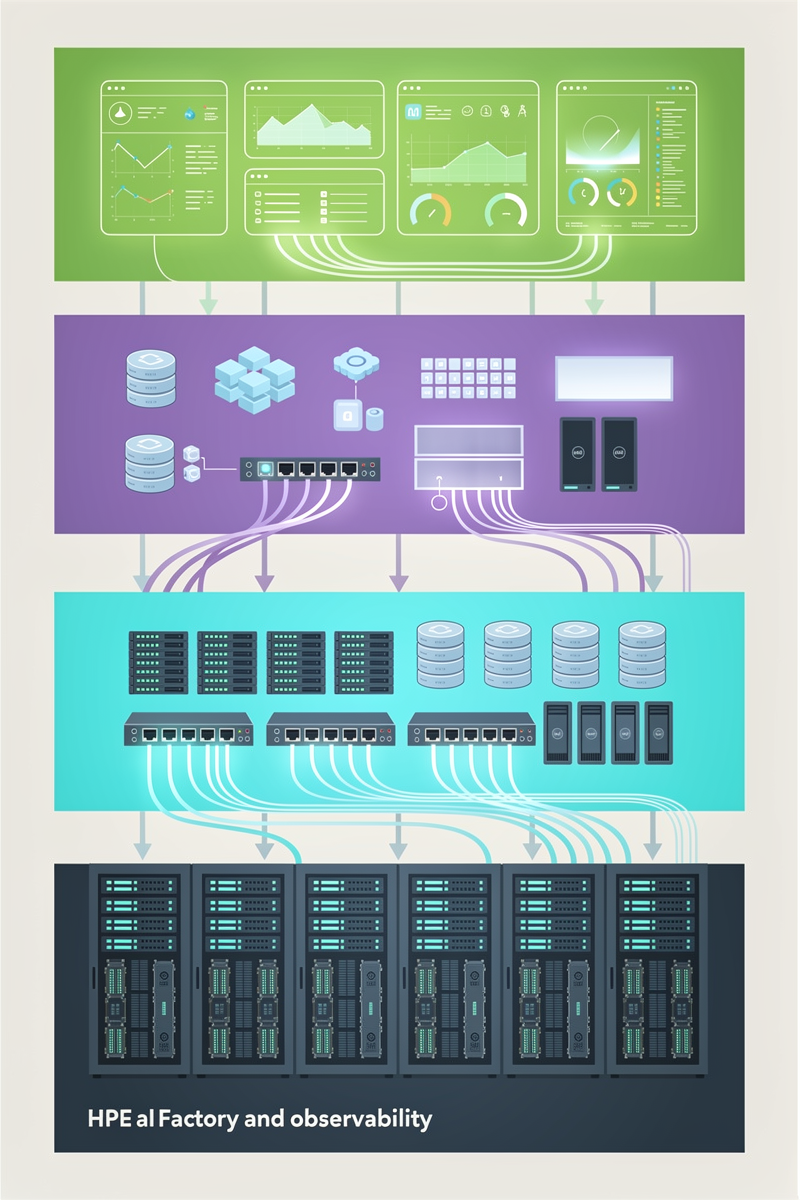
- 컴퓨트 계층: HPE Cray·ProLiant 서버에 탑재된 NVIDIA H100·H200·Blackwell GPU 노드가 Nemotron 3 추론·파인튜닝 클러스터의 코어를 이룹니다.
- 스토리지 계층: HPE Alletra·ECS 등 고대역 병렬 스토리지로 체크포인트, 피처 스토어, 벡터 인덱스를 통합 저장합니다.
- 네트워크 계층: NVIDIA Spectrum 스위치와 InfiniBand·RoCE 기반 저지연 패브릭으로 노드 간 통신과 GPU 간 AllReduce를 최적화합니다.
- 소프트웨어 계층: Kubernetes, HPE Ezmeral, NVIDIA AI Enterprise, vLLM/SGLang, TensorRT-LLM이 결합된 AI 팩토리 레퍼런스 아키텍처 스택이 핵심입니다.
- 운영·관측 계층: 전력·온도·트래픽·토큰/초를 모니터링하는 통합 관제와 과금·쇼백(showback) 기능으로 AI 공장 운영을 표준화합니다.
Nemotron 3 추론 스택 선택 가이드: vLLM·TensorRT-LLM·SGLang
Nemotron 3는 vLLM, TensorRT-LLM, SGLang 등 다양한 서빙 스택을 공식 지원해 선택지가 넓습니다. 고성능 배치 디코딩, RoPE 스케일링, 캐시 관리 최적화가 공통된 핵심 포인트입니다.
고처리량 API 서빙에는 vLLM이 유리하고, 온프렘 어플라이언스나 저지연 서비스에는 TensorRT-LLM이 적합한 경우가 많습니다. SGLang은 프롬프트 라우팅과 컴포지션에 강점을 가져 복잡한 에이전트 워크로드에 적합합니다.
세 스택 모두 Nemotron 3의 MoE 구조와 1M 컨텍스트를 고려해 설계돼 고효율 추론 성능과 처리량 최적화를 실현합니다. 적절한 조합을 설계하면 동일 GPU 수로 더 많은 동시 세션을 처리해 GPU 자원 최적화 및 비용 절감 효과를 얻을 수 있습니다.
온프렘·코로케이션에서 AI 공장 구축 시 필수 인프라 체크리스트
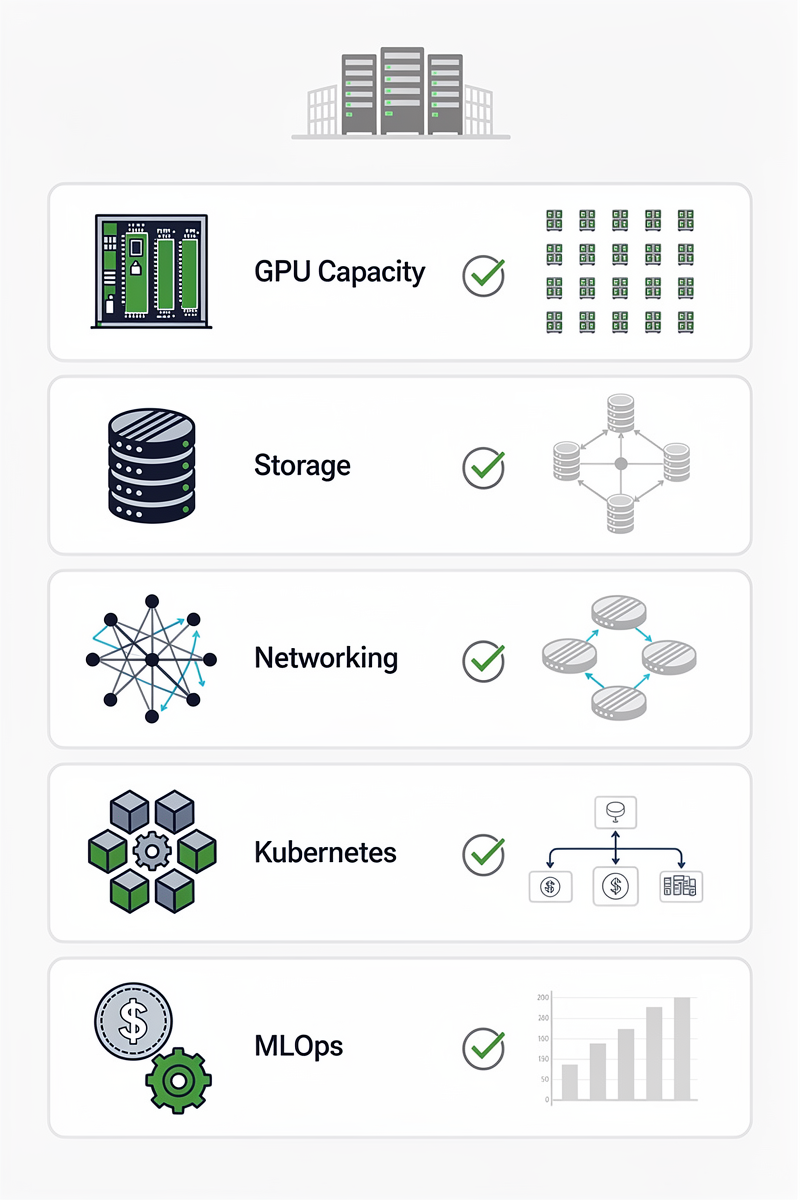
- GPU 계층: H100/H200·Blackwell급 GPU 수량, 메모리 용량, NVLink·NVSwitch 구성을 확인합니다. 엔터프라이즈 온프렘 구축 시 전력·냉각 여유도 함께 산정해야 합니다.
- 스토리지·백업: 모델·데이터·로그를 분리한 스토리지 계층과, 주기적 스냅샷·오브젝트 스토리지 백업 전략을 정의합니다.
- 네트워크 토폴로지: 노드 간 대역폭, ToR/스파인 구조, 이중화 구성, 동서 트래픽 모니터링 계획을 수립합니다.
- 쿠버네티스·스케줄러: GPU 오버커밋 전략, 네임스페이스 분리, 멀티테넌시 정책을 포함한 클러스터 아키텍처를 설계합니다.
- MLOps·LLMOps 스택: 파이프라인 오케스트레이션, 피처/벡터 스토어, 프롬프트 버전 관리 체계를 구축해야 합니다.
- 비용·효율: GPU 사용률, 토큰/달러, kWh/토큰 지표를 모니터링해 GPU 자원 최적화 및 비용 절감 목표를 수치로 관리합니다.
Llama·Mistral·DeepSeek과 비교한 Nemotron 3의 실제 포지셔닝
Nemotron 3 vs 동급 오픈 모델: 스펙·성능 비교로 보는 위치
| 모델 | 파라미터·아키텍처 | 컨텍스트 길이 | 대표 벤치(대략) | 특징 |
|---|---|---|---|---|
| Nemotron 3 Nano 30B | 31.6B total / ~3.6B active, 하이브리드 Mamba-Transformer MoE | 최대 1M | MMLU ~78.6, LiveCodeBench ~68, RULER 512K ~70.6 | Qwen3 30B 대비 처리량 최대 3.3배, 롱컨텍스트·코드·에이전트 특화 |
| Qwen3 30B-A3B | 30B dense/부분 MoE | 128K 수준 | MMLU ~81, LiveCodeBench ~66-67 | 전통 강자, Nemotron보다 처리량은 낮지만 일부 벤치 점수는 앞섬 |
| GPT-OSS-20B | 20B dense | 128K 내외 | MMLU·코드 중간대 | 경량 20B급으로, Nemotron 대비 효율·성능 모두 낮은 편 |
| Llama 3.2 11B | 11B dense Transformer | 128K | MMLU ~73 | 범용 경량 모델로, 롱컨텍스트·코드 성능은 Nemotron 3 Nano보다 한 단계 아래 |
| Mistral 8x7B | 8×7B MoE | 128K | MMLU ~70 | 효율 좋은 MoE지만, 롱컨텍스트·에이전트 벤치는 Nemotron·Qwen3 30B에 열세 |
| DeepSeek/코더 33B | 30~33B 코드·수학 특화 | 128K | HumanEval·MATH 상위권, MMLU 70대 | 코드에 강하지만, 최신 Nemotron 3 Nano·Qwen3 30B가 일부 코드·추론 벤치에서 1~5%p 상회하는 보고 존재 |
Nemotron 3의 강점 5가지: 토큰 효율·1M 컨텍스트·GPU 최적화
- 1M 토큰 초장문 컨텍스트 지원: 엔터프라이즈급 로그·문서·대화 세션을 한 번에 넣고 분석하는 롱런 워크로드에 적합합니다.
- MoE 기반 토큰 효율: 활성 파라미터 3.6B 수준으로 30B dense급 품질을 내면서 연산량을 줄여 고효율 추론 성능과 처리량 최적화를 달성합니다.
- 엔터프라이즈 GPU 친화성: H100·H200·Blackwell와 TensorRT-LLM·vLLM·SGLang 조합을 전제로 설계돼 데이터센터 GPU 활용률이 높습니다.
- 에이전트·코드·RAG 벤치 상위권: LiveCodeBench, MATH, HumanEval 등에서 동급 오픈 모델 대비 우수한 성능으로 멀티 에이전트·코딩·검색 워크로드에 적합합니다.
- Qwen3 30B 대비 처리량 우위: H200 기준 8K·16K 시나리오에서 약 3.3배 처리량을 보여 토큰당 비용을 크게 낮출 수 있습니다.
Nemotron 3가 최적 선택이 되는 조직 프로필 5가지
- GPU 풀스택을 이미 NVIDIA로 표준화한 대기업: DGX·Spectrum·InfiniBand를 보유하고, 벤더 통일로 운영 복잡도를 줄이려는 조직.
- 멀티 에이전트 AI 시스템 구축 비중이 높은 플랫폼 팀: 플래너·코더·실행기 등 다수 에이전트를 운영하며, 긴 대화 히스토리와 툴 호출 로그를 1M 컨텍스트로 유지하고 싶은 팀.
- 온프렘·코로케이션을 중시하는 금융·공공 기관: 데이터 주권과 규제를 이유로 클라우드 LLM API 의존을 줄이려는 조직.
- GPU 자원 최적화 및 비용 절감 압박이 큰 SaaS 기업: 자체 GPU 클러스터에서 LLM API를 만들어 고객사에 판매하는 B2B 플랫폼.
- 코드·RAG·분석까지 하나의 패밀리로 통일하고 싶은 엔지니어링 조직: 도메인별 다른 모델을 섞기보다 Nemotron 3 기반으로 에이전트·코딩·검색을 통합 운영하려는 팀.
결론
Nemotron 3 패밀리는 1M 컨텍스트, 하이브리드 Mamba Transformer MoE, 오픈 가중치를 기반으로 Qwen3 30B 대비 최대 3.3배 처리량을 제공합니다. NVIDIA Open Model License는 상업적 활용과 온프렘 배포를 허용하고, AI 팩토리 레퍼런스 아키텍처는 GPU·스토리지·네트워크·소프트웨어를 아우르는 기업용 AI 공장 설계안을 제시합니다.
이 조합은 클라우드 LLM API만으로 해결하기 어려운 데이터 주권, 비용, 지연 시간 문제를 하이브리드·온프렘 전략으로 전환할 수 있게 만듭니다. NVIDIA Nemotron 3는 멀티 에이전트, 코딩, 로컬 RAG까지 하나의 오픈소스 LLM 패밀리로 통합하려는 조직에 현실적인 선택지입니다.
지금 보유한 GPU 아키텍처, 데이터 위치, 주요 워크로드(에이전트·코드·검색 비중)를 기준으로 Nemotron 3 적합성을 수치로 평가해 보시기 바랍니다. 3개월 이내 작은 온프렘 PoC나 코로케이션 기반 시범 서비스를 설계해 토큰당 비용과 품질을 클라우드 LLM API와 직접 비교하는 실험을 진행하는 편이 좋습니다.
